Tip #0 -- go to Document Properties and turn off compression. It will make saving and loading application much faster. Yes, it takes more disk space now but you're not going to send such large application by mail anyway.
Mitigate long reload times
Once you've got tens of millions of records you probably don't want to perform full reload after every small change in the script. Some people use built-in debugger for limited runs, although you can have better control over limited reloads using a variable and FIRST prefix for LOAD statements that operate with large tables. Example:
LET vFirst = 1000;//00000000;
FIRST $(vFirst) LOAD ...
In this case you can do quick short runs with a limited set of data either to check correctness of script syntax after small changes or verify transformation logic. Remove semi-colon and double slash for a full load. Make sure that you have enough zeroes.
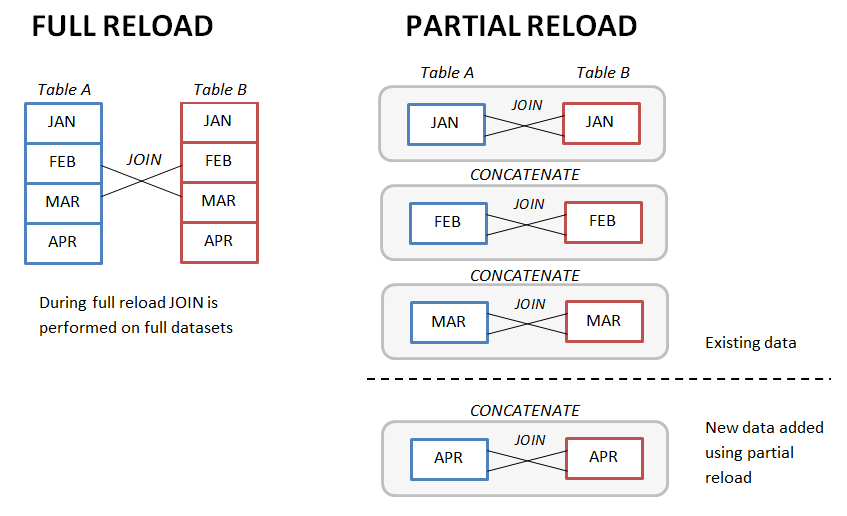
You would probably want to reduce even full reload times as much as possible. In some cases, if data model allows logical partitioning of data it's better to switch to partial reload as the main reload mode for updating the application with new information. In this case data model isn't dropped entirely, so you can append new chunks of data to it instead of building everything from scratch. Full reload can be left for emergency cases, when entire data model has to be rebuilt.
This technique is especially useful when you work with monthly (weekly, daily) snapshots and you need to join them (you might want to do this for denormalization as a way of performance improvement discussed below). In this case instead of joining two full tables you can join monthly snapshots first, and then concatenate results month by month, using partial reloads (see picture below).
To make it more manageable, it's better to store monthly snapshots in individual QVD files -- one QVD per month.