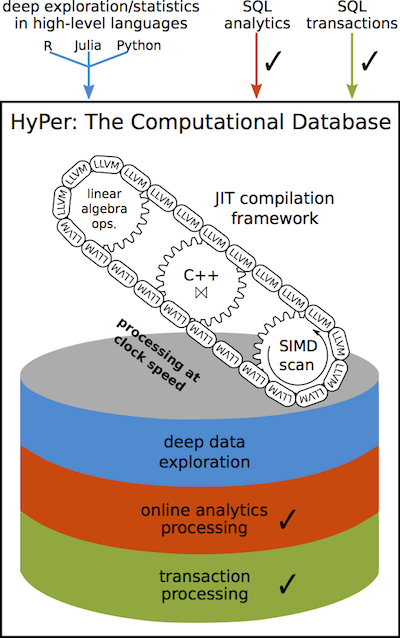
HyPer claims to have high performance in both transactional and analytical types of workloads, achievable even on ARM architectures. It uses many smart techniques like virtual memory snapshoting to run long and short queries on the same datasets, one-the-fly compilation of queries into low-level code, adaptive indexing, hot clustering for query parallelization and many others (see HyPer overview).
Does it mean that Tableau becomes a database company? Apparently no. First, because that's not what they do, and second, because HyPer is rather an academic technology research rather than a market-ready product.
To me this acquisition is very much like Qlik's acquisition of NComVa a few years ago. Let me explain it a bit:
NComVa was a small company that built interactive Javascript data visualizations. From what I understand Qlik Sense to some extent exploits the expertise acquired from NComVa. Qlik is very good at engineering highly optimized data engines, but academic data visualization and user experience is hardly can be counted as their core competence (I'll write a separate post on it). So Qlik needed some "brain injection" that led to birth of Qlik Sense.
With Tableau the situation is opposite -- their competence in data visualization and usability is outstanding, however high-performance in-memory data processing has never been a strong point in Tableau's agenda -- the idea was to piggyback existing relational DBMSes. To remind you, Tableau only recently switched to a 64-bit architecture and introduced multi-threaded query execution for their in-memory engine.
Therefore, the acquisition of HyPer is a long needed "brain injection" of top-notch data processing expertise. And it may change things significantly for Tableau customers, competitors and Tableau themselves.
I would suggest that in 1-2 years (not earlier) Tableau will introduce something like a super-cache -- the ability to hold big amounts of data (up to 1 TB or more) in memory, query it instantly with sub-second response times, and update in real-time.
Interesting questions are: whether it will require data modelling, how data will be loaded, and whether it will scale horizontally. The latter question is the most interesting, because Qlik, the closest Tableau's competitor, doesn't scale horizontally meaning that a single dataset can't be split across several nodes that are queried in parallel. HyPer hints at distributed data processing, so it could be possible that the "super-cache" will scale horizontally, which can be a big deal.
All in all, the acquisition is an intriguing twist of story. It will be interesting to see how it unfolds.
[1] http://www.tableau.com/about/press-releases/2016/tableau-acquires-hyper
[2] http://www.tableau.com/about/blog/2016/3/welcome-hyper-team-tableau-community-51375
